
The secret behind OpenWhisk scalability
How is it possible for OpenWhisk to scale automatically and distribute workload in the cloud starting from simple functions, written in different programming languages?
The secret lies in its internal architecture. For the end-user, all it takes is to send his code as a function to the “cloud”. A lot of things then happen internally. The function is assembled into an executor, called runtime. There are runtimes for Javascript, Python, Java, Go, and many other programming languages.
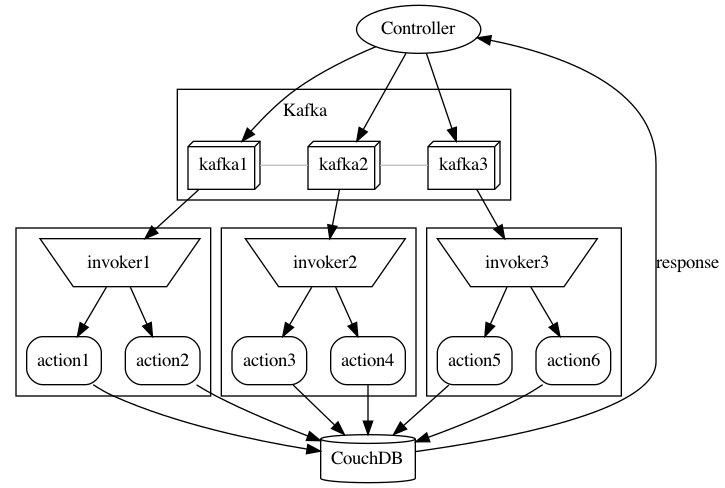
Requests are carried out by a complex architecture. The starting point is a controller, that collects requests and sends them to a Kafka message queue.
A group of Invokers listens to Kafka’s requests; the less loaded one picks a request to serve it and localize an available runtime. If no runtimes are available it creates a new one. Once it gets the resources, the Invoker executes the request.
Finally, the result is collected in a No-SQL database and sent back to the controller to return it back to the user. And the loop restarts.