
Picking the right level of abstraction
The problem of the “right level of abstraction” is long-standing in computer science. When I studied “programming languages” at university, the textbook defined computer science as “the art of building hierarchies of abstract machines”.
At first, I didn’t understand, then I realized it’s true: progress in Information Technology consists mainly in using existing “machines” to build on top other, simpler and easier to use, computing machines.
For example, starting with the processor, you build on top of it a system programming language, like C or C ++. Above we have more advanced programming languages such as Python or Java. Again, on top of your programming language you use a framework, like the ubiquitous web frameworks. And so on.
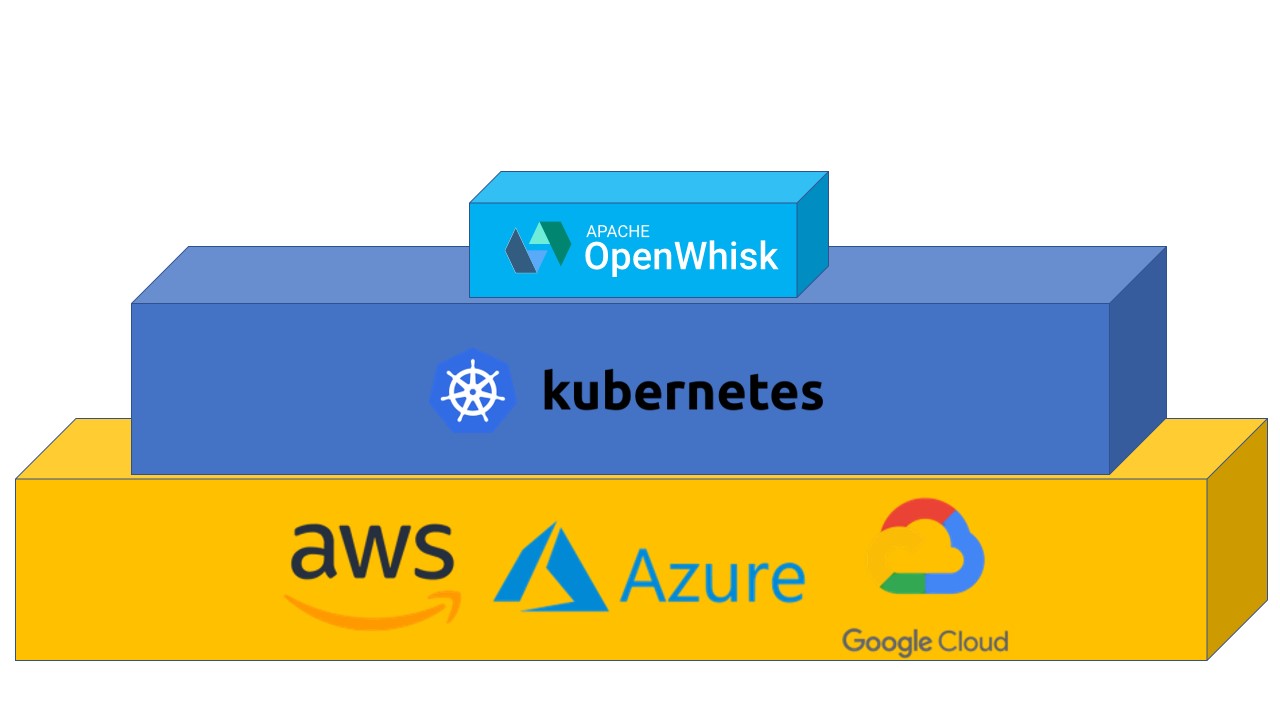
This same logic applies to the cloud: you use the pre-existing layer to build environments that are easier to program. The first and most complex level is what a cloud provider offers, which is very complex. It is not surprising people prefer to use an abstraction layer like Kubernetes. But still, Kubernetes is far from being optimal for developing applications. OpenWhisk builds on top of it to offer an easy-to-use platform for developing cloud-native applications.